As mentioned in the last article (https://dataengineeringfromscratch.blogspot.com/2021/02/what-is-apache-spark.html), the spark framework primarily comprises of Drivers, Executors and Cluster Manager. Now its time to further go in detail of how exactly spark runs on a cluster (Internally & Externally)
What is a Cluster?
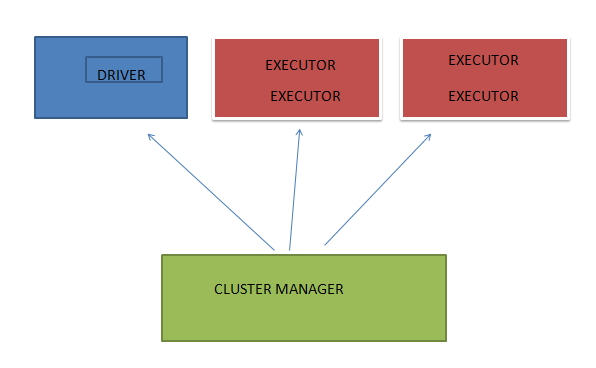
Spark is a parallelly run framework comprising of multiple machines/servers involved in the task execution. Cluster is nothing but a formal way to say group of machines/servers. Now, it makes more sense why Cluster Manager is called so. This is because it manages the cluster which comprises of lot machines.
What is a Worker Node?
Worker node are the ones on which cluster manager assign drivers and executors when an Spark application is submitted to the Cluster Manager
What is Execution Mode?
An Execution Mode gives you an idea of how resources are physically allocated when one runs a spark application. It is majorly of three types:
1) Cluster Mode
2) Client Mode
3) Local Mode
Cluster Mode:
This the mode in which the spark application is submitted to the Cluster Manager which launches the driver process on one of the nodes in addition to the executor processes. Thus, cluster manager is responsible for all spark related processes. This is the most common execution mode.
Client Mode
This is the mode in which the spark application is submitted through a client machine which acts like the driver and the cluster manager only manages the executor processes.
Local Mode
This the mode which runs the spark application on a local machine. Here we do not run machines in parallel but we have threads running in parallel. This the mode through which one can start implementing spark application in the process to learn spark.
Right, so now we are done with different modes of execution. With this level of understanding, we can now dive into how exactly the spark process runs on the cluster both internally and externally.
External Process
1. The spark application is submitted to the Cluster Manager.
2. The Cluster Manager places the driver on a node. Now, the application has started executing on the cluster.
3. The driver now starts running the user code. The user code must include a SparkSession(will discuss this in detail. for now, just think of it as a gateway through which we use all spark functionalities).
4. This SparkSession interacts with the cluster manager to start the executor process. The number of executors and various configuration are set while starting the application.
5. The execution begins and the driver schedules tasks onto each executors. The executors work on the task and finally sends out status to driver with failure or success.
6. The driver exits with success or failure and cluster is stopped by the cluster manager.
Internal Process
Now, lets have a brief dig into how internally spark works.
1. The user code has a SparkSession which instantiates Spark and SQL context that would be used to write code for processing data.
2. The code runs in which the data is ingested from the source and moved to the sink.
In the next article, I will show you a small piece of code and explain how the user code is turned into a physical plan of execution (Internal Process).
For now, just know that the spark code is divide into two forms : Transformation and Action. It is only when the code comes across an Action that we see an output after all the Transformation is implemented on the data. Please do not get overwhelmed by the last statement!!
For now, just think of a car making industry as a user code.
Transformation - This is the process where we install different parts of car to form a structure(physical plan).
Action - This is the process when we start the car and different parts of the car starts to function one by one and the car finally moves !!!!


Comments
Post a Comment