Data has become huge now. And in foreseen future, we expect it to grow exponentially. With this much of Data(BigData), besides storage, computing is a major bottleneck that is faced by Organizations, thus opening prospects for Data Engineer.
Apache Spark is by far, arguably, the best way to achieve this in a UNIFIED and PARALLEL way.
UNIFIED
Apache is not limited to only transforming data. It is one stop solution to ingest data i.e. simple data loading, transforming data, querying(SQL) data, Machine Learning and also dealing with Streaming computation. All these could be achieved by using Spark. The user can opt for any programming languages of his/her choice - Scala, Java, Python and R, all of which has libraries for diverse tasks, as mentioned above.
PARALLEL
What makes Spark so special? Why there is such a huge demand for Spark resources nowadays?
Say, Task to be achieved is to clean a room. Assigning one cleaner to complete the task definitely would be more time consuming than having more than one cleaner.
Similarly, a task could be done more quickly if we distribute the task among various computers . Using parallelism, Spark distributes tasks into multiple systems/servers thus reducing burden on individual systems to achieve the target. This does not mean that an individual who is just starting off cannot practice on his/her local system for small processes.
The following question that arises after reading the analogy is - 'Getting more cleaners would be more heavy on pocket'. Without a doubt this a valid question. However, given the era in which we live in, for an organization, time is the most important parameter. Also, scaling up in terms of number of parallel CPUs has become much more cheap and viable.
SPARK ARCHITECTURE
Lets explain this using an analogy. Say, A team of developers has been given a task of developing a software. With sheer enthusiasm, the team starts working on the task only to realize that each member has been working on the UI part. Though the team is very talented, they realized there is a requirement for a Team Lead who would be assigning different tasks to different individuals only to hear the status of their progress at the end of the day. He will also be the point of contact for the client.
After some good progress, one of the team members asks for 3 days off to the Lead via an email. The Lead is so occupied with the project that he does not look at the mail. In absence of any response, the team member loses interest in the job as he felt he was not heard. On further contemplation, it was found there is a dire need for an HR manager who looks after the executor and helps negotiate between the lead and the developers.


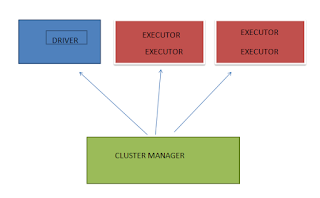
In Spark Architecture,
Team Lead = Driver
Developers = Executors
HR Manager = Cluster Manager
So, The Driver is the one which is the control node. It assigns small tasks to each executors. Also, like Team lead was the Point of Contact, The driver is the one which takes in the code from the Application and data from the input source.
The Executors are the one which complete the tasks assign to them by the driver and reports back to the driver.
The Cluster Manager is the one which negotiates resources between the driver and the executors. Popular cluster managers are Standalone, YARN (used in Hadoop), Mesos.
That's it in this blog. I will go deep down the drivers, executors and cluster manager in following blogs. Also, i will cover how things work internally and externally. This will be followed up with detailed explanation of Structured APIs and Low Level APIs.



Comments
Post a Comment