How Spark runs on Cluster?
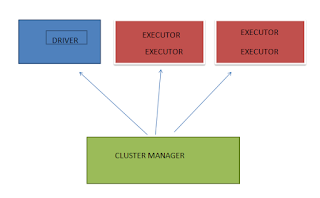
As mentioned in the last article ( https://dataengineeringfromscratch.blogspot.com/2021/02/what-is-apache-spark.html ), the spark framework primarily comprises of Drivers, Executors and Cluster Manager. Now its time to further go in detail of how exactly spark runs on a cluster (Internally & Externally) What is a Cluster? Spark is a parallelly run framework comprising of multiple machines/servers involved in the task execution. Cluster is nothing but a formal way to say group of machines/servers. Now, it makes more sense why Cluster Manager is called so. This is because it manages the cluster which comprises of lot machines. What is a Worker Node? Worker node are the ones on which cluster manager assign drivers and executors when an Spark application is submitted to the Cluster Manager What is Execution Mode? An Execution Mode gives you an idea of how resources are physically allocated when one runs a spark application. It is majorly of three types: 1) Cluster Mode...
